(ตอนที่ 1) พยายามอ่านและจัดรูปแบบข้อความในไฟล์หลายล้านบรรทัด โดยใช้ทรัพยากรให้น้อยที่สุด ด้วย Spring WebFlux

สวัสดีปีใหม่ครับ เปิดปีใหม่ด้วยการเล่าเรื่อง technical challenge ให้ฟังละกัน เพราะจำได้ว่า ไม่ได้เอาเรื่อง technical กลับมาเขียนลง blog นานมากละ งั้นขอหยิบเอาปัญหาที่เจอแล้วดูน่าสนใจเมื่อตอนปลายปีมาเล่าให้ฟังกันครับ
เมื่อช่วงปลายปี 2025 เราได้รับโจทย์ให้ทำ service สำหรับ process ตัว batch file แล้วแปลงข้อความที่อยู่ใน batch file แปลงเป็นข้อความที่ได้รับการจัดรูปแบบแล้วส่งขึ้น Kafka เพื่อให้ service อื่นๆที่เกี่ยวข้อง สามารถ consume เอาไปทำอย่างอื่นต่อได้ โดย business requirement คร่าวๆก็ประมาณนี้ หลังจากที่ทีมนั่งดูสิ่งที่ต้องทำ ก็ breakdown ออกมาได้ประมาณนี้
- อ่านข้อความในไฟล์ ที่อยู่ในรูปแบบ CSV file ซึ่งมีหลายล้านบรรทัด
- แปลงเอาข้อความใน CSV file มาจัดให้อยู่ใน object เพื่อให้ง่ายต่อการใช้งานต่อ
- เอา object ที่จัด มาทำการ aggregate ให้อยู่ใน format ที่เตรียม produce ขึ้น kafka
- produce ข้อความที่ aggregate แล้ว ขึ้น Kafka
หลักๆนี่คือสิ่งที่ต้องทำ ทีนี้เราก็ตั้ง goal ในเรื่องของ technical challenge เอาไว้ เพื่อเพิ่มความท้าทายให้กับทีม
- application ต้องยังทำงานได้บนสภาพแวดล้อมที่มีทรัพยากรต่ำ แม้จะเจอ message หลักล้านเข้ามา (cpu : 500 millicore, ram : 512mb)
- เราใช้ PostgreSQL อยู่แล้ว แต่ไม่ได้ใช้เยอะ (db.t4g.medium) เราไม่อยาก scale database เพราะเรื่องของ cost ในการ scale database ค่อนข้างสูง โดยเราจะคงไว้ด้วย size นี้ ไม่เพิ่ม (ทั้ง production และ staging)
- application ต้อง gracefully shutdown เมื่อกำลัง process ข้อมูล เมื่อมี node ใหม่เกิดขึ้น ต้องทำงานต่อจากเดิมได้
และเราเลือกสิ่งที่เป็น common stack ของเราก็คือ Spring WebFlux เพื่อให้ทีมสามารถดูแลต่อได้ เอาละ เริ่มได้
การอ่านไฟล์
นี่ก็เป็นโจทย์แรกขึ้นมาทันทีครับ 😄 หลายคนคงบอกว่า
เห้ย ก็ Java มันจะอ่านไฟล์ขึ้นมาแบบ stream มันจะยากตรงไหนฟร๊ะ
จริงครับ มันจะยากตรงไหน มันยากตรงที่ตัดสินใจใช้ WebFlux นี่แหละครับ 😄
เพราะเราต้องเลือก operator ของ Project reactor ที่เหมาะกับการทำงานในรูปแบบ thread blocking และ synchronous นี่แหละครับ เพราะตัว Spring WebFlux มันถูกพัฒนาบนพื้นฐานของ non-blocking io โดยใช้ framework ของ Project reactor เป็นพื้นฐาน พอนำมาพัฒนากับงานที่เป็น blocking io ก็ต้องคิดนิดนึงว่าจะเอายังไง และแล้วก็เราก็ได้คำตอบ
Flux.usingWhen

ถ้าไปดู document ในเว็บ project reactor มันก็จะงงๆแหละครับ มันทำงานอะไรของมัน เอาเป็นว่าผมอธิบายง่ายๆละกัน ว่ามันทำงานยังไง
โดย operator ตัวนี้ เหมาะสำหรับงานที่มี lifecycle ชัดเจน ก็คือ
เปิด -> ทำงาน -> ปิด
โดยถ้าเรามาดู use case ที่เราจะใช้ ก็จะเป็นประมาณนี้ครับ
อ่านไฟล์ -> stream ข้อมูลออกไป -> ปิดและลบไฟล์ทิ้ง
โดยเราสามารถเขียนโค้ดออกมาได้ประมาณนี้
Flux.usingWhen(
Mono.fromCallable {
Files.lines(path) // เริ่มต้นด้วยการอ่านไฟล์ออกมาเป็น stream
}.subscribeOn(Schedulers.boundedElastic()),
{ stream -> Flux.fromStream(stream) }, // แปลง stream ให้กลายเป็น Flux เพื่อให้ Subscriber นำไปใช้ต่อ
{ stream ->
Mono.fromRunnable {
stream.close()
}.flatMap {
Mono.fromCallable {
Files.delete(path)
}
}.subscribeOn(Schedulers.boundedElastic())
}, // หากทำงานเสร็จ ลบไฟล์ทิ้ง ปิด stream ไปด้วย
{ stream ->
Mono.fromRunnable {
stream.close()
}.subscribeOn(Schedulers.boundedElastic())
}, // หากเกิดข้อผิดพลาดขึ้น ให้ปิด stream เพื่อคืน memory ให้ด้วย
{ stream ->
Mono.fromRunnable {
stream.close()
}.subscribeOn(Schedulers.boundedElastic())
}, // หาก reactor pipeline ถูก cancel ให้ปิด stream เพื่อคืน memory ให้ด้วย
)แค่นี้ เราก็จะได้โค้ดที่ handle ตัว lifecycle ในการจัดการไฟล์เรียบร้อย ไม่ว่าจะทำงานสำเร็จหรือไม่ ก็สามารถ handle การทำงานต่างๆในการจัดการไฟล์ได้อย่างครบถ้วนละ พร้อมทำในส่วนของ business ต่อไป
เริ่ม Aggregate ข้อมูลและปรับ Structure ของ Payload
เอาจริงๆนะ ถ้าเป็นการแค่การอ่าน file จาก CSV แล้วแปลงเป็น object แล้ว produce ไป Kafka มันก็ไม่เห็นจะยากตรงไหนเลยเนอะ หลายคนคิดแบบนี้แน่นอน แต่ถ้าชีวิตมันง่ายขนาดนั้น ก็ดีหนะสิครับ
ประเด็นคือ ชีวิตมันไม่ได้ราบรื่นขนาดนั้นครับ เรามีไฟล์บางประเภทที่ต้อง aggregate ก่อน ก่อนที่จะ produce ไป Kafka ได้
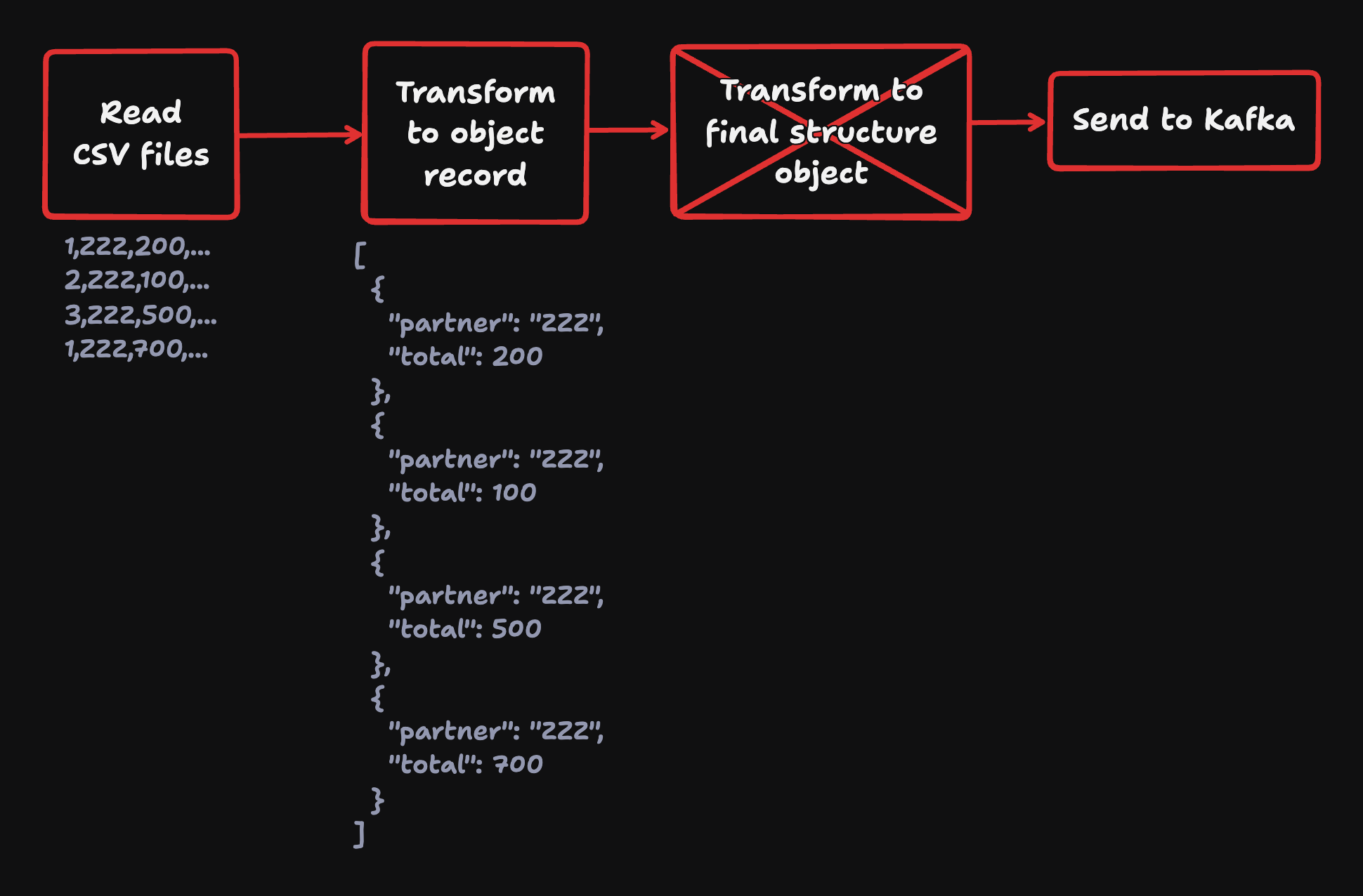
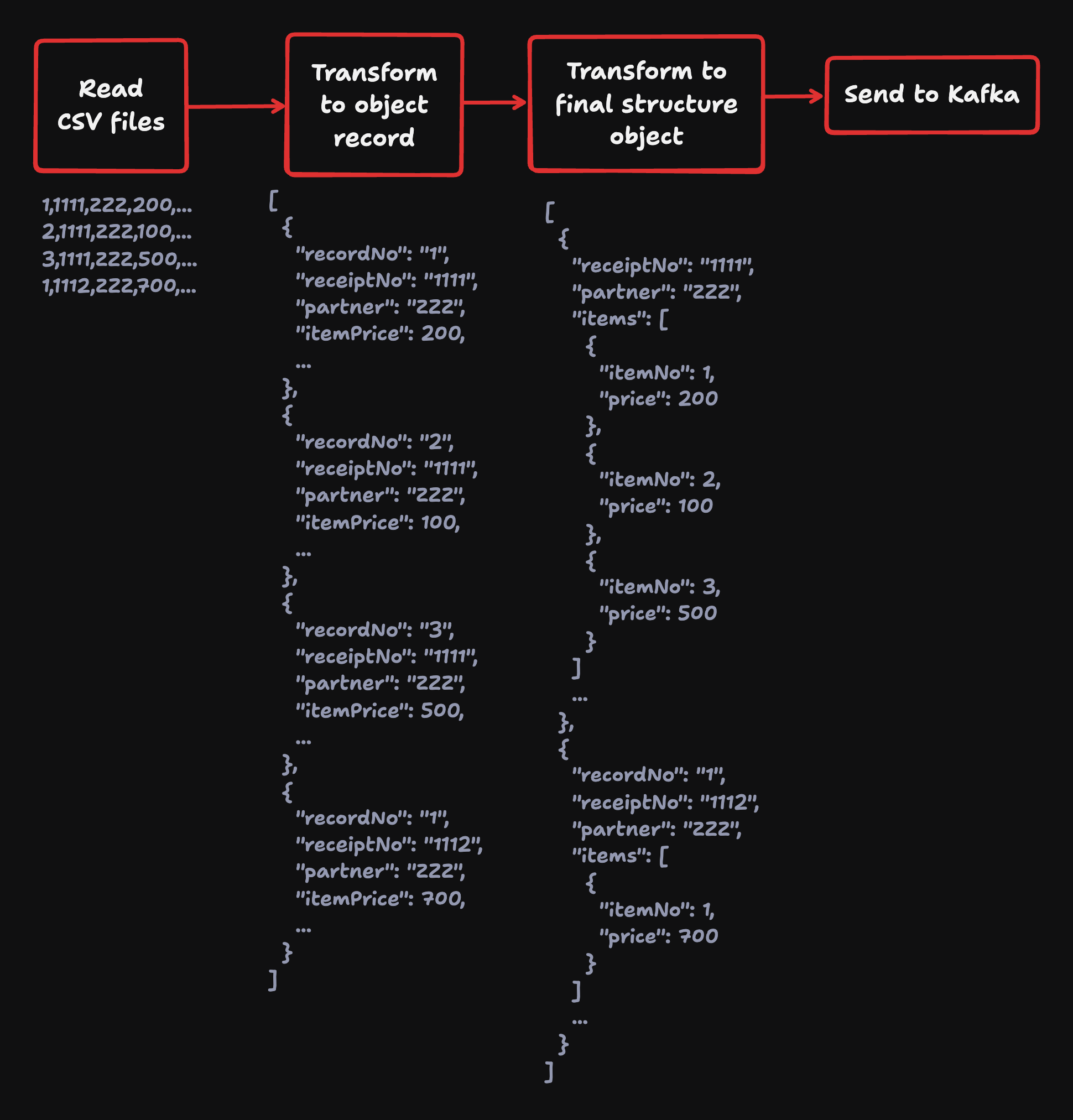
แล้วเราจะทำยังไงดีนะ แน่นอนว่าเราตั้ง goal เลยว่า พอจะมีทางไหน ที่เราจะไม่แตะ database หรือต้องแตะ database น้อยที่สุด และแน่นอน เวอร์ชันแรกที่เราทำเพื่อ quick win ตอนแรกคือ
อ่านไฟล์ทั้งหมดมา แล้ว collectList หลังจากนั้นค่อย aggregate ต่อ
ถ้าใครนึกไม่ออก เราไปดู code snipplet กัน
Flux.from(... streaming reader)
.flatMap {... csv to object record}
.collectMap {... create map object with key,value , key is receiptNo }
.map {... aggregate and revise payload structure }ถ้าอ่านโค้ดแล้วก็รู้สึก ไม่มีอะไรนี่หว่า ก็ทำงานได้ปกติหนิ แต่นั่นแหละครับ เราก็ลองปล่อยให้ระบบทำงานไปดูเรื่อยๆ แรกๆก็ทำงานได้ปกติ ในระดับไฟล์ที่ record ไม่เยอะมาก จนกระทั่ง เราได้เจอกับไฟล์ที่มี record หลักแสนถึงล้าน
Record หลักหมื่นพอทน Record หลักแสนพอเลย
ใช่ครับ เจอ OutOfMemoryError: Java heap space ทันที สาเหตุของการบึ้มครั้งนี้ เพราะหลังจากเราอ่านข้อมูลจากไฟล์เป็น stream เข้ามาก็จริง แต่ใน logic เราทำการ collectMap ขึ้น ทำให้เกิดการ buffer ของที่อ่านมาใส่ memory ไว้ก่อน แล้วค่อยทำ logic ต่อไป เมื่อมี memory ไม่เพียงพอ ก็เกิด OutOfMemoryError: Java heap space ขึ้นครับ
แล้วจะทำยังไงดีละทีนี้ ผมยังมีความมุ่งมั่นที่จะไม่ยอมใช้ database ในการทำ aggregate อยู่ดีครับ เลยลองไป research ดูว่า มีใครจะช่วยฉันได้ไหมนะ จนกระทั่งได้รู้จักกับ operator ตัวนึงของ Project reactor ที่ช่วยชีวิตเราได้ นั่นคือ...
Flux.windowUntilChanged

และแน่นอน ถ้าไปอ่าน document ของ Project reactor ก็จะงงๆอีก (ตามเคย) เอาเป็นว่าเดี่ยวผมอธิบายให้เข้าใจง่ายๆละกันครับ
ตัว operator .windowUntilChanged จะเอาไว้สำหรับแบ่งกลุ่ม (Windowing) คล้ายกับการ Group By ครับ แต่สิ่งที่แตกต่างจาก Group By (.groupBy) คือ
-
.windowUntilChangedจะตรวจจับข้อมูลที่ไหลอยู่ใน Flux ว่ามีการเปลี่ยนแปลงตามเงื่อนไขที่บอกหรือไม่ หากเปลี่ยนแปลง จะ emit ข้อมูลชุดใหม่ออกไป .groupByจะต้อง collect ข้อมูลทั้งหมดก่อน แล้วจึงค่อยๆหาชุดข้อมูลและจัดกลุ่มเข้าด้วยกันตามเงื่อนไขที่เราบอกไป
ดังนั้น ข้อควรระวังในการใช้ .windowUntilChanged คือ กรณีที่ของที่ไหลมา ตัว value ที่เอามาใช้ในการทำเงื่อนไขเกิดไม่ต่อเนื่องกัน ทั้งๆที่เป็นค่าเดียวกัน จะทำให้ operator มองว่าเป็นคนละค่ากัน เช่น
AAABBBCCAA -> windowUntilChanged -> [AAA],[BBB],[CC],[AA]
หลังเราตรวจสอบข้อมูลในไฟล์เบื้องต้นที่เรามี ก็โอเค ข้อมูลหมายเลข receiptNo เรียงลำดับดีอยู่นะ เลยโอเค ลองกับสิ่งนี้ดูกัน
Flux.from(... streaming reader)
.flatMap {... csv to object record}
.map {
Pair(receiptNo, recordPayload) // pair key/value for make the easy to extract data
}
.windowUntilChanged { it.first } // handle receiptNo was change or not
.concatMap { reciept ->
reciept
.map { it.secord }
.collectList() // collect all records has same receiptNo
.flatMap {
... aggregate and revise payload structure
}จากโค้ดด้านบน จะเห็นว่า เราเปลี่ยนโค้ดบางส่วนไป เพื่อเพิ่มจังหวะในตรวจจับการเปลี่ยนแปลงของ receiptNo ว่ามี receiptNo เปลี่ยนแปลงหรือไม่ หากไม่ ไม่ต้อง emit Flux เส้นใหม่ออกมา แต่ให้รวบข้อมูลที่ไหลทั้งหมด เป็น list (.collectList()) เราก็จะได้ list เล็กๆ นำไป aggregate ต่อได้ ไม่ทำให้ memory บวม
หากพบว่า receiptNo เปลี่ยนแปลงไป จะทำการ emit Flux เส้นใหม่ออกมา แล้วทำแบบเดิมไปเรื่อยๆ ทำให้เราประหยัดทรัพยากรลงเยอะมาก และระบบทำงานได้อย่างราบรื่น
แต่ถ้าเรื่องมันจบง่ายแบบนั้น มันก็ไม่ใช่เราหนะสิครับ หลังจากนั้นเราพบว่า มี Partner อยู่เจ้านึง ทำการเขียนไฟล์มา ด้วยหมายเลข receiptNo ไม่เรียงลำดับ!! โอ้วจ๊อชชช!!
เรามาดูตอนหน้ากันครับ ว่าเราจะแก้ปัญหานี้ยังไง รวมถึงกับตอนทำ gracefully shutdown ว่าเรามีวิธี handle สิ่งนี้ยังไง ในตอนหน้าครับ 😸